Speechki Without Copyright

Transforming Text into Natural Speech with AI-Powered Voice Technology
The Voice Revolution in Digital Content
In today’s fast-paced digital landscape, the demand for high-quality audio content has never been greater. Speechki, accessible through AI-1.art, represents a groundbreaking advancement in text-to-speech technology, offering natural-sounding voice synthesis without the copyright restrictions that typically limit voice generation platforms. This innovative solution is transforming how businesses, educators, and content creators produce audio content.
What sets Speechki apart from traditional text-to-speech services is its commitment to copyright-free output. Unlike many voice synthesis platforms that impose usage limitations or claim rights to generated audio, Speechki ensures that the voices created through its platform belong entirely to the user. This fundamental shift in ownership model opens up new possibilities for content creation across various industries.
Advanced AI Voice Synthesis
Speechki leverages cutting-edge artificial intelligence and deep learning algorithms to create remarkably natural-sounding speech. The platform uses neural network models trained on thousands of hours of human speech, enabling it to capture the subtle nuances, intonations, and emotional inflections that make synthesized speech sound genuinely human. The technology goes beyond simple text-to-speech conversion to deliver voice output that listeners find engaging and authentic.
The system supports multiple languages, accents, and voice characteristics, allowing users to select the perfect voice for their specific content needs. From professional narrations to character voices for creative projects, Speechki’s AI can adapt to various contexts and requirements while maintaining exceptional audio quality.
Copyright-Free Voice Generation
The copyright-free aspect of Speechki’s service is particularly valuable in commercial and creative applications. When you generate speech through the platform, you retain complete ownership of the resulting audio files. This means you can use the synthesized speech in any project—commercial or personal—without worrying about licensing fees, usage restrictions, or attribution requirements.
Unrestricted Usage Benefits
- Commercial Applications: Use generated speech in advertisements, product demos, and corporate presentations
- Content Creation: Incorporate synthesized voices into YouTube videos, podcasts, and social media content
- Educational Materials: Create audio versions of textbooks, courses, and learning resources
- Accessibility Features: Develop voice interfaces for applications and websites
- Creative Projects: Use voices in animations, games, and multimedia presentations
Practical Applications Across Industries
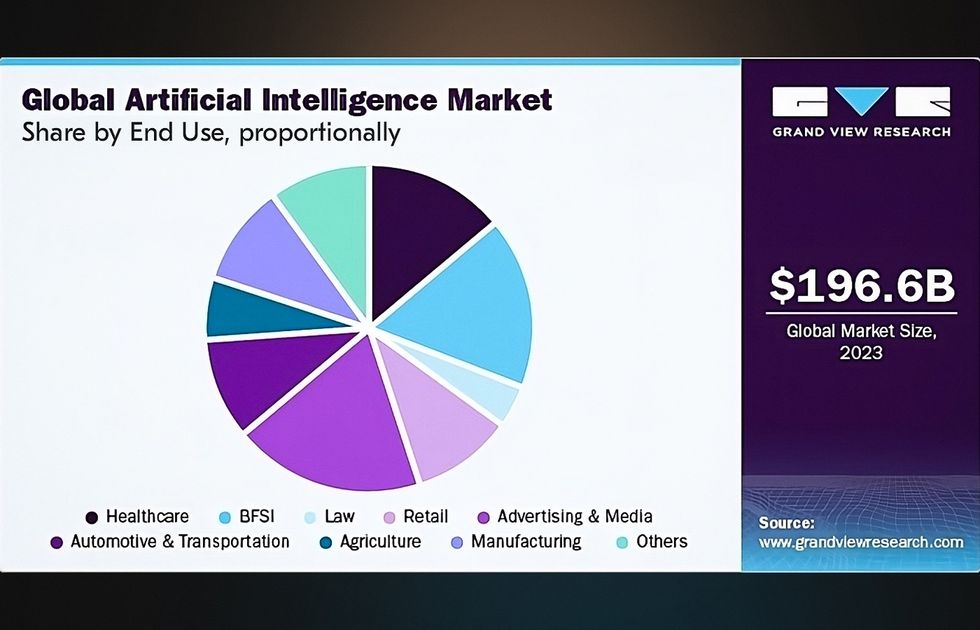
Speechki’s copyright-free voice synthesis technology has transformative implications across numerous sectors. Educational institutions can create audio versions of learning materials without copyright concerns. Businesses can develop professional voice-overs for training videos and customer communications. Content creators can produce audio content at scale without the cost and complexity of hiring voice actors.
E-Learning and Education
Educational platforms can use Speechki to convert written content into engaging audio lessons, making learning materials more accessible to diverse learning styles and needs. The copyright-free nature ensures that institutions can distribute these audio resources widely without legal complications.
Content Marketing
Marketers can create audio versions of blog posts, articles, and social media content to reach audiences who prefer listening over reading. The ability to generate high-quality voice content quickly and without copyright restrictions enables more dynamic and inclusive content strategies.
The Technology Behind Natural Speech
Speechki employs sophisticated neural text-to-speech (NTTS) technology that represents the cutting edge of voice synthesis. The system uses deep learning models that understand context, punctuation, and linguistic patterns to generate speech that flows naturally. Unlike older concatenative systems that stitch together pre-recorded sounds, Speechki’s AI generates speech from scratch, resulting in smoother, more natural-sounding output.
The platform’s ability to handle complex text structures, technical terminology, and multiple languages makes it suitable for a wide range of applications. The AI continuously learns and improves, ensuring that the quality of synthesized speech keeps pace with the latest advancements in artificial intelligence and computational linguistics.
Key Benefits for Users

Cost Efficiency
Eliminate the expense of hiring voice actors and recording studio time for audio content production
Time Savings
Generate high-quality audio content in minutes rather than the days required for traditional recording
Scalability
Produce large volumes of audio content consistently without variations in voice quality
Flexibility
Make instant changes to audio content by simply editing the source text
Ethical Considerations in Voice Synthesis
While Speechki offers powerful capabilities for voice generation, the platform is designed with ethical considerations in mind. The AI is trained to create original voice outputs rather than replicating specific individuals’ voices without permission. Users are encouraged to employ the technology responsibly and transparently, particularly when the synthesized speech might be mistaken for human recording.
The copyright-free model ensures that users have clear rights to the audio they generate, but it also places responsibility on users to employ the technology in ways that respect privacy, avoid deception, and contribute positively to their respective fields.
The Future of Audio Content Creation
Speechki represents a significant milestone in the evolution of text-to-speech technology. By combining advanced AI with a copyright-free model, the platform makes high-quality voice synthesis accessible to creators and businesses of all sizes. As artificial intelligence continues to advance, we can expect even more natural-sounding speech synthesis, with better emotional expression, improved language handling, and more versatile voice options.
The ability to generate copyright-free audio content effortlessly opens up new possibilities for accessibility, content distribution, and creative expression. Speechki is not just improving how we convert text to speech—it’s transforming how we think about and interact with audio content in the digital age.